GeForce RTX 4090 Laptops? But why?! Well…stick with me here…


I’ve spent a great deal of time looking at benchmarks lately. It’s the nature of working with a new generation of videocards that you end up watching literally days worth of benchmarks over and over as you really plumb the depth of the capabilities of a new piece of technology. Also inevitably, there ends up being a class of videocards that I often skip – the mobile versions. There’s always a tradeoff between performance, heat, power usage, and price that always stands heavily on that latter part of the scale. When I saw some PCs shipping with two power bricks, I was terrified at what we’d be looking at for an RTX 4090. I’ve reviewed the PC version (along with the rest of the line), so I knew that the laptop version of the RTX 4090 would be powerful, but with what tradeoffs? I got my hands on Razer’s new Razer Blade 16 with the intent of finding out precisely that.

First and foremost, I’m not reviewing the Razer Blade 16 here – this is purely a deep dive into why anyone would need something like a mobile version of an RTX 4090. A quick peek under the hood of the laptop version of the NVIDIA GeForce RTX 4090 is revealing. It is based on the AD103 graphics processor, sporting 9728 cores, 16GB of GDDR6 memory, and operating on a 256-bit bus width. The GPU operates at a base frequency of 930 MHz, with a boost at 1455 MHz, and memory running at 1750 MHz. This is a tremendous amount of power but how does it translate to actual gaming? Would this be a GPU that would greatly lean on NVIDIA’s DLSS 3 to hit the high marks, or would the 304 Tensor Cores, 76 RT cores, Ada Lovelace architecture deliver the sort of power you’d expect from a 4000 series GPU, and what sort of portable generator and turbine fan would you need to power and cool it? That’s when I saw that this GPU only uses 80 watts of power (well, more accurately, it can go as low as 80, with 115+25W for “Balanced” mode, and 150+25W for flat out on the Razer device). There’s no way this thing is gonna deliver. Right? My Predator Triton 500 has a 230 W power supply, and at load will draw nearly all of it.
One of the biggest advantages of the 4000 series of GPUs is that it supports DLSS 3.0. As such, it’s able to take advantage of a staggeringly high amount of power, but further bolsters it with AI-powered frame generation. Again, with only 80 watts of power at the GPUs disposal, I’d want to see if NVIDIA was leaning on DLSS 3, or if the hardware could handle rasterized gameplay just as well. As such, I ran all of the benchmarks with all of the bells and whistles enabled, including DLSS 3 when available, or DLSS 2 with any additional options I could muster, and again with all of the assists turned off. I tilted my chair back and started the process. I was surprised at the results, as I suspect you will be.
Before we get to the results, let’s get a quick rundown on the specs of this laptop, and some general terms to understand:
The first thing I want to define is TDP. TDP stands for Thermal Design Profile. This number is an amalgamation of information that indicates power consumption and maximum heat values — you can read the power primer whitepaper here. For example, on a CPU you’ll use this to determine how much cooling is required, as well as the power supply you’ll need to run it. For a GPU, the cooling is often already included, but the power supply question still remains. In both cases, that maximum heat threshold can be a clear indicator of a performance problem as both devices will commonly heat throttle to help ensure they aren’t damaged. It also will tell you the amount of power, in watts, each device can utilize. To better illustrate it, a desktop RTX 4090 has a TDP of 450W. An RTX 3080 has a TDP of 350W. This device has a TDP of 175W. Keep these numbers in mind when we get to the performance indicators.
The next term we’ll want a refresh on is Max-Q, because that term has changed once again, and funny enough despite it being a great differentiator between generations, NVIDIA has even stopped using the term to define the borders between their laptop generations. Just the same, I’m going to go through each here as they really do tell you a great deal about the technology
We are now in the fifth generation of Max-Q, and with each iteration there is not only a refinement of what’s included, but also meaningful improvements. Let’s start with Gen 1.
The first generation of Max-Q was more of a set of bars that said “you have to be this tall to ride this ride”. The max efficiency of the GPU at peak and optimized power settings are obvious, but NVIDIA also defined effective thermal characteristics and overall efficiency of design. Some of these were fairly broad, so the implementation was a bit all over the place. Still, it got the ball rolling.
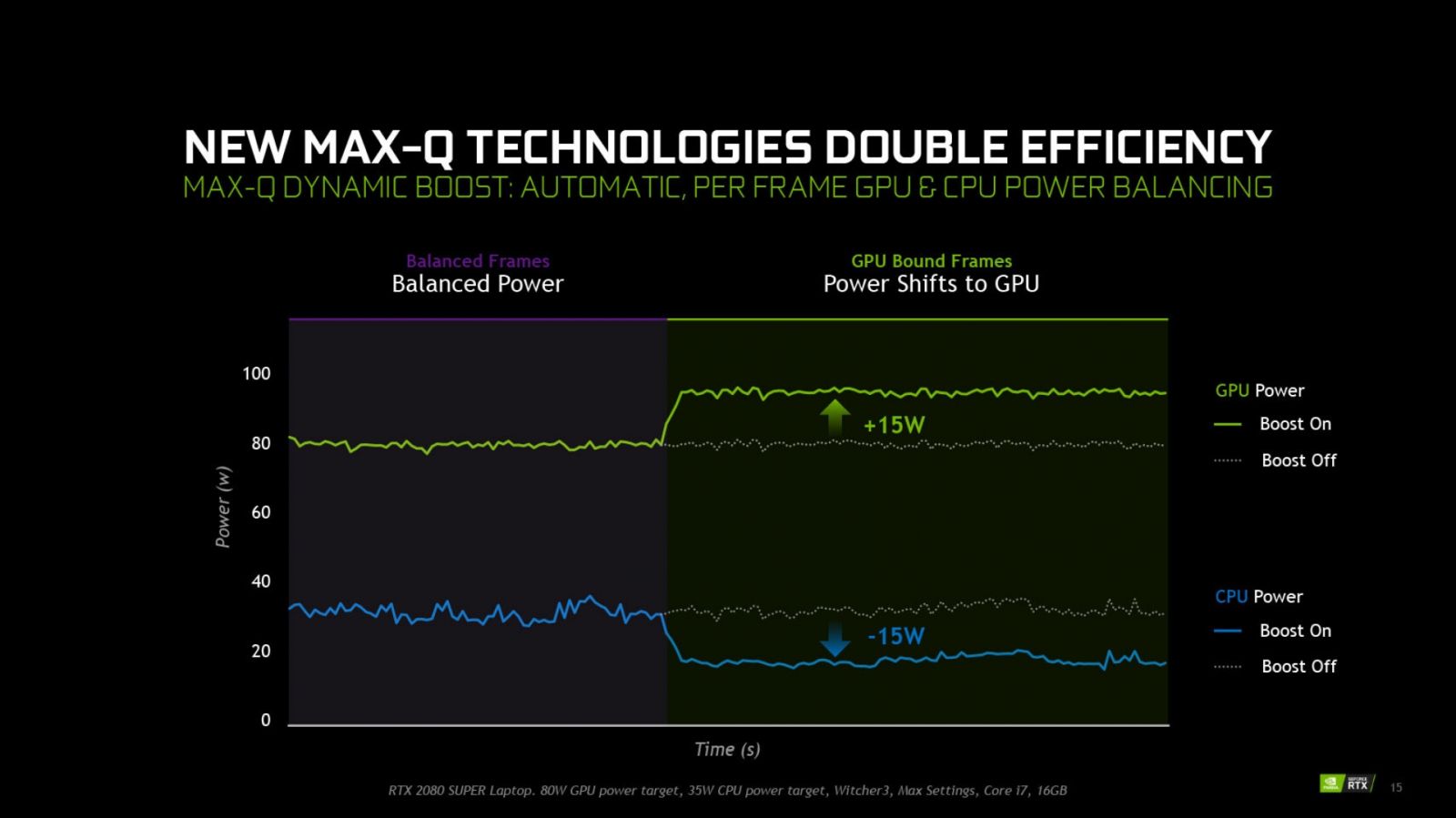
The second generation of Max-Q has everything present in Gen-1 Max-Q, but also added Dynamic Boost (a system-wide power controller which manages GPU and CPU power, according to the workload on the system — here’s how you turn it on), Next Gen Regulator Efficiency (roughly 15% of power is lost at the voltage regulator — this is now captured and given to the GPU instead), Advanced Optimus (allows the laptop to turn off the GPU to save battery life, instead using the IGP on the CPU), and DLSS 1.0 (the first iteration of AI-driven upsampling — click here to see how DLSS works at a very deep level).
Max-Q’s third generation gave us DLSS 2.0 (and with it, upwards of 75% higher AI-assisted framerate at higher resolutions, sharper images after upsampling, further customization of upsampling options, and a new AI network that could be used more broadly), and ReBAR (short for resizable BAR, which allowed the GPU and CPU to communicate to access either the entire frame buffer, or just portions of it, in a concurrent fashion rather than queueing to improve speed and efficiency). It also brought iterations to Dynamic Boost and Whisper Mode. Dynamic Boost 1.0 could only send power from the CPU to the GPU, but couldn’t do the reverse — 2.0 fixes that. Whisper Mode 2.0 fixed the obvious problem of GPUs (mostly the 3000 series) that sounded like jet engines on takeoff. Whisper Mode 2.0 might as well be magic. It uses a combination of speed adjustments and, crazily enough, frame timing, to intelligently adjust the speed and heat curve to reduce overall noise. If you gave me 1000 guesses, I wouldn’t have imagined that’s how Whisper Mode 2.0 worked, but somebody at NVIDIA did, and my ears are appreciative.

Fourth gen Max-Q gave us Battery Boost 2.0, Rapid Core Scaling, and CPU Optimizer. Battery Boost 2.0 pairs up with the aforementioned Optimus improvements to stretch battery life as far as possible, while still maintaining solid framerate and frame pacing, even when just on battery power. CPU Optimizer, as the name suggests, uses the interplay between the CPU and GPU to wring additional efficiency out of the overall platform — upwards of 2X in some cases. It does so by pushing the CPU to the top of the peak efficiency instead of the power curve, preserving power that could be otherwise wasted. It also uses direct API control to ensure workloads are aimed at whichever device would be best to do the work, or is most available.
5th Gen Max-Q, the most recent, has a whole host of goodies exclusive to the 4000 series of GPUs; DLSS 3, Ultra-Low Voltage GDDR6, Tri-Speed memory control, and Ada High Efficiency on Chip Memory. DLSS 3 brings with it AI-driven frame generation, as well as what can only be described as a ridiculous improvement to overall framerate, for a slight and occasional tradeoff in visual quality. Ultra-low voltage GDDR6 is, as the name suggests, memory modules specifically built for maximum speed (9001 Mhz in this case, because somebody out there had to make it “over 9000!”) while using as little power as possible. Paired with Tri-Speed memory control, that lower voltage GDDR6 can effectively “clutch” down to lower levels to further maximize power savings when needed. The last one, Ada High Efficiency On-Chip Memory might be a little vague, but it’s referring to these technologies combined into a new architecture that improves power efficiency and massive improvements in bandwidth. In fact, the effective GDDR6 boost clock hits between 1455 and 2040 MHz, utilizing a 256-bit pipeline, to provide a 14GBps effective output. That’s the exact same amount as a desktop variant of an NVIDIA GeForce RTX 3070, but at a fraction of the power. That means the 4090 Max-Q is equivalent to the RTX 3070 desktop version, right? Well…only one way to find out.
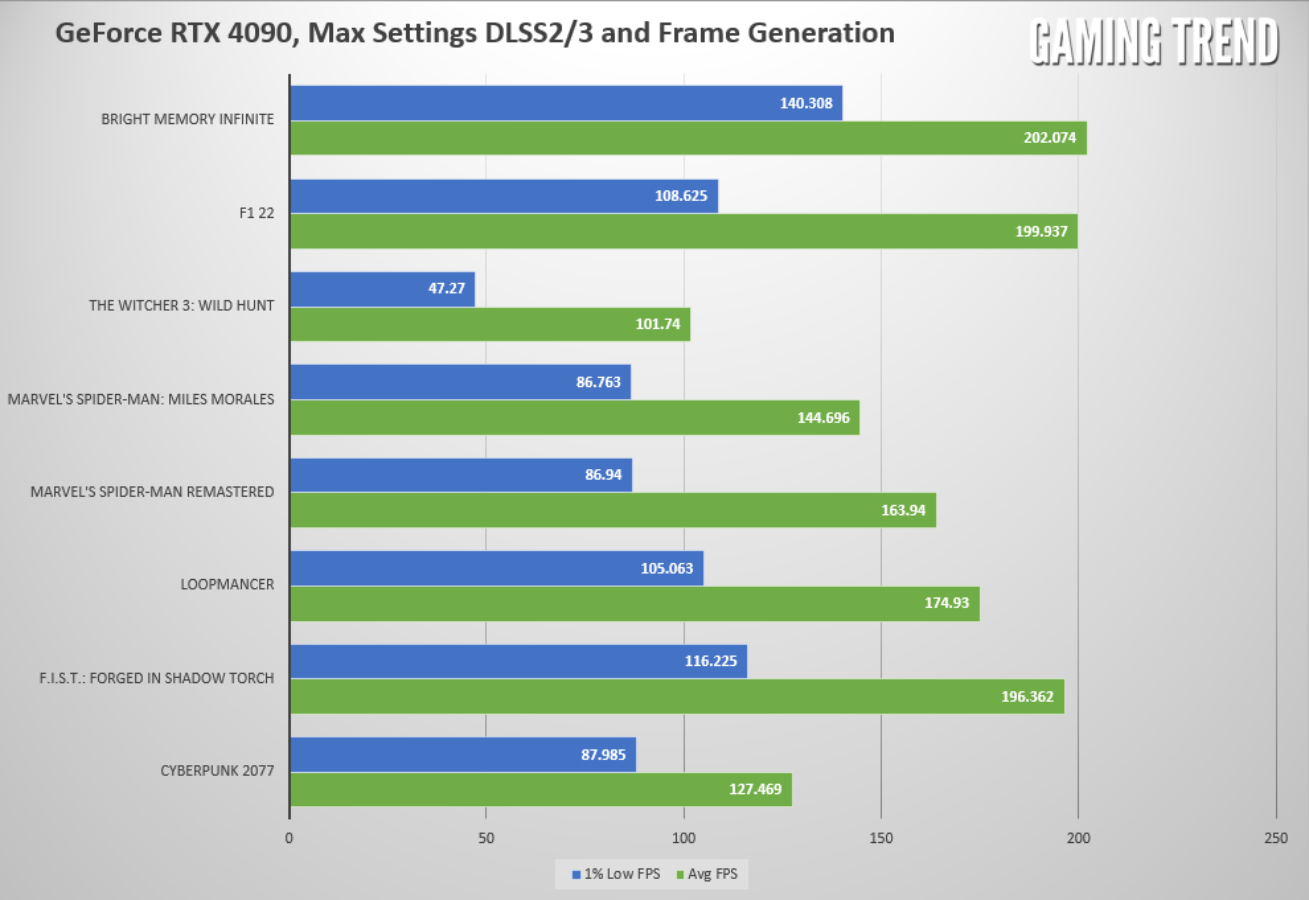
All of the tests below are ran at 1440p resolution, and have been run at least three times with DLSS set to quality, and all options set to maximum. They were then re-ran without the benefit of DLSS – a fully rasterized benchmark. This will showcase what the GPU is capable of with the benefit of AI frame generation. While the system can and does run things incredibly smoothly and at high framerate at 4K, at this view distance you’re probably better off at 1440p resolution and enjoying a higher framerate. As you’ll see, however, there’s so much raw power in this GPU, it’s very likely that it won’t matter which resolution you choose – there are plenty of frames to go around.
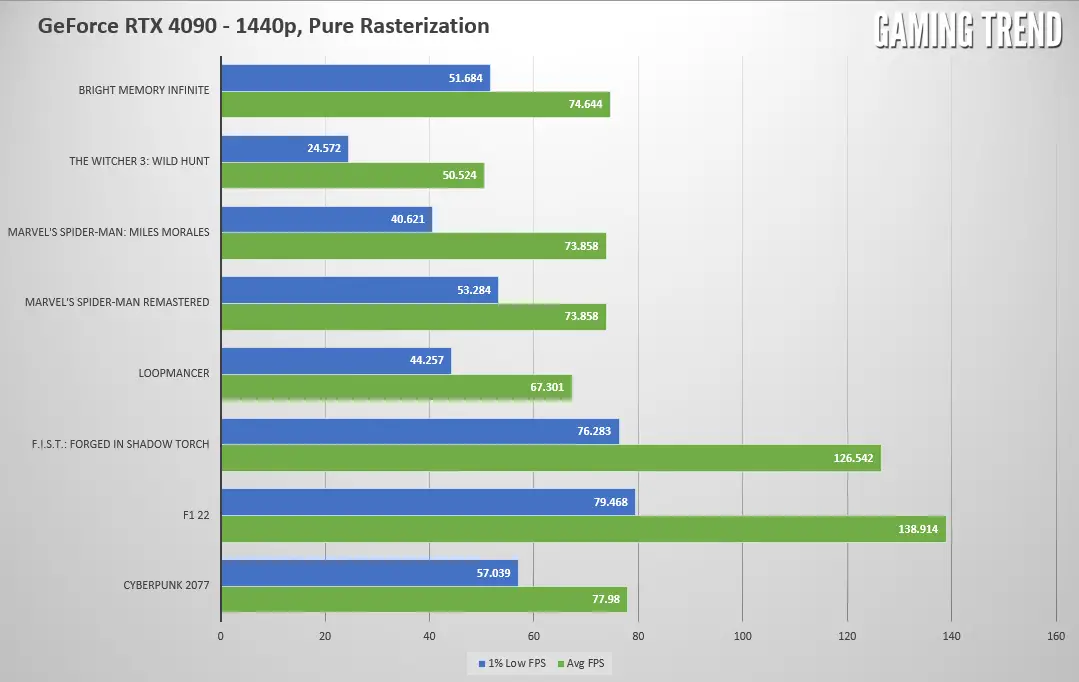
And now that same graph, ran exactly the same way, but without DLSS or frame generation enabled — pure, unadulterated, rasterized frames.
Beyond the obvious and significant framerate improvements, these 4000 series devices also come with a significant boost to productivity tools as well. I do a great deal of video rendering, so I have an appreciation for the 4080 and 4090 GPUs as they both have dual AV1 encoders to speed up that process. In fact, rather than running a bunch of artificial rendering tests, I simply went about my daily work, rendering videos for all of our game coverage. Comparing the rendering time on a 4K/60 gameplay video on a 3000 series device is roughly 1:1. If the video is 60 minutes long, it’ll likely take you 60 minutes to render it. My 2000 series devices were slightly longer, but the difference between them and the 3000 series cards being a decent jump but certainly not double. That’s not the case here – the same video I rendered on my RTX 3080 was completed in literally half the time. The dual AV1 encoder made light work of any video rendering jobs I threw at it, and frankly the improvement could be worth the purchase alone for those who render their video on site. I can already think ahead to shows like E3, PAX, and Gamescom where speed and the sheer volume of video we’ll need to process justifies a 4000 series laptop, and I suspect some of you can think of similar use cases.
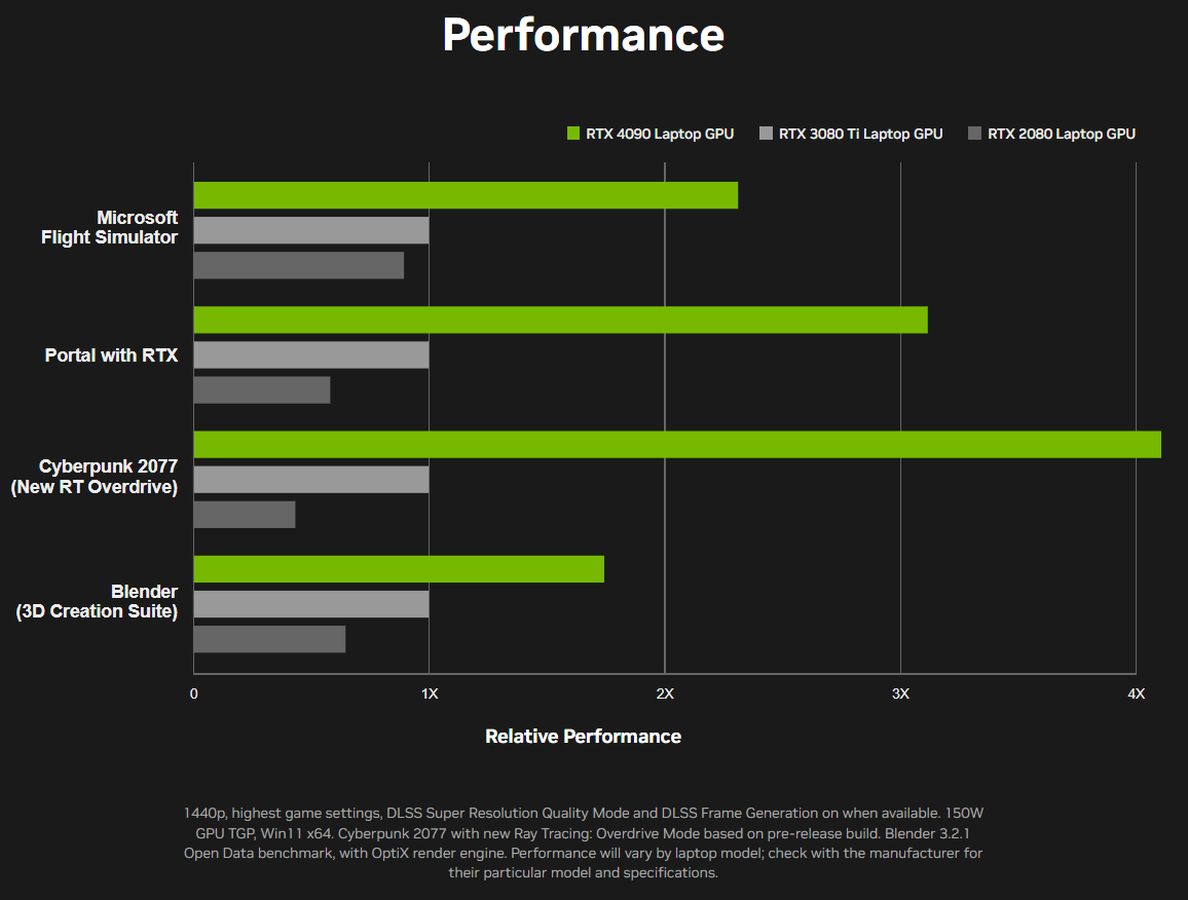
While I don’t design graphical work, there is also a significant improvement for Blender workloads. NVIDIA claims that on the low end it’s closer to a 1.7X improvement, and on the high end it’s upwards of 2.4X the speed of a 3080 Ti Laptop GPU. While I can’t say I know how to operate Blender enough to confirm this myself, on paper it certainly sounds like a pretty solid jump for those of you who work in that field.
All of this measurement loops back around to the central question – why would anyone need a laptop equipped with an RTX 4090? I don’t know if I’ve answered that for you, but having used this Razer Blade 16 for a few weeks now, I don’t want to send it back. The fact that it can deliver as much power as the last generation of flagship desktop computers, but at a fraction of the power consumption, and somehow without sounding like a harrier jet is astounding to me. I think about the utility of having that at my fingertips for development, and the capability of rendering videos at lightning speed while on site at a conference, and it’s alluring. There’s no doubt that these are expensive – at the time of writing, the Razer Blade 16 will set you back $4300. You’ll need to figure out if the additional speed and portability is worth it for you. Given that this device is meant as a highly-portable desktop replacement, delivering unparalleled power in an unbelievably compact passage, it’s certainly worth the argument.
